|
Dieser Teil der Arbeit entwickelt eine Datenstruktur, die darauf abzielt, sowohl einfachen Zugriff auf die Struktur, als auch auf die eigentlichen Inhalte der SGML-Dokumente zu erlauben. Zusätzlich wird eine Möglichkeit gegeben, auf die SGML-Dokumente als Ganzes zuzugreifen. Aus der an den Speicher gestellten Anforderung gängige Datenbankmanagementsysteme zu unterstützen, leitet sich weiterhin der Anspruch ab, eine Datenstruktur zu entwickeln, die einfach aufgebaut, erweiterbar und auf andere DBMS übertragbar ist.
Wie bereits in Abschnitt 4.3 beschrieben, werden die SGML-Dokumente als Datei (Bitstrom) zwischengespeichert, können also sequentiell verarbeitet werden.
Um getrennt auf Tags und Taginhalte zuzugreifen, liegt es nahe Tags und Daten in zwei Datenbankklassen separat abzulegen. Ein solches Konzept wurde bereits unter Kapitel 2.2 vorgestellt. Der einfache Zugriff auf das gesamte SGML-Dokument ist hier nicht gegeben. Beide Klassen müssen getrennt ausgewertet und dann gemischt werden.
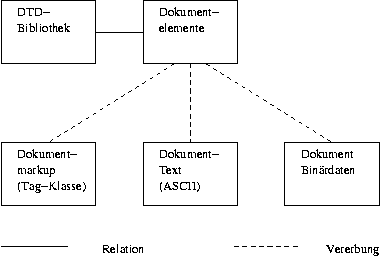
Das hier vorgestellte Konzept nutzt aus diesem Grund den Mechanismus der Vererbung, der in objekt-orientierten Datenbanken zur Verfügung steht. Dazu wird eine im objekt-orientierten Sinne abstrakte Basisklasse eingeführt und von dieser getrennte Klassen für Tags und Taginhalte abgeleitet.
Basisklassen erlauben es, daß Abfragen über die Basisklasse und alle vererbten Datenbankklassen durchgeführt werden. Gleichzeitig definiert die Basisklasse eine Datenstruktur, auf der alle vererbten Klassen aufbauen. Zu dieser Datenstruktur gehören Informationen, wie die eindeutige Dokumenten-ID und eine fortlaufende Nummer, die analog zur Reihenfolge der Elemente im SGML-Dokument während des Speicherns vergeben wird.
Fragt man über die Basisklasse alle Datensätze mit der gleichen Dokumenten-ID ab und sortiert diese nach der fortlaufenden Nummer, so erhält man das originale SGML-Dokument als Ergebnis. So ist die für digitale Bibliotheken wichtige authentische Wiederherstellung der gespeicherten Informationen auf einfachste Weise gewährleistet.
Auf die Bedeutung des Strukturbaums bei der Verarbeitung von SGML-Dokumenten wurde bereits in Kapitel 2.2 hingewiesen und die vereinfachte Speicherung des Strukturbaums in Datenbanken beschrieben. Die Tag-Klasse sieht in dieser Datenstruktur zwei Felder vor, die die fortlaufende Nummer des Bruder-Tags und des Sohn-Tags aufnehmen. Da die Elemente der Dokumente der Reihe nach gespeichert werden, kann der Strukturbaum bzw. die Bruder- und Sohn-Tags während des Speicherns berechnet werden, erfordert also keine separaten Berechnungen nach dem Speichervorgang.
Der Zugriff auf den Strukturbaum erfolgt direkt über die Tag-Klasse, in der unter Angabe der Dokumenten-ID und Auswahl des Elements mit der fortlaufenden Nummer „Eins“ die Wurzel des Strukturbaums abgefragt werden kann. Unter Verwendung von Depth-First-Search ([Knu73]) kann der Baum durchlaufen werden.
Binäre Informationen wie Bild- oder Tondaten können in SGML-Dokumente eingebunden werden. Viele Datenbanksysteme unterscheiden jedoch prinzipiell zwischen Text (ASCII) und Binärdaten. Deshalb wurden innerhalb des Datenmodells ebenfalls zwei Klassen eingesetzt, die zum einen reine Textdaten zum anderen Binärdaten aufnehmen.
Das beschriebene Datenmodell ist in Abbildung 4.2 dargestellt.
In den einzelnen Klassen werden folgende Informationen abgelegt:
Zu bemerken ist, daß eine Klasse jeweils die Tag-, Text- oder Binärinformationen aller gespeicherten SGML-Dokumente beinhaltet und nicht für jedes einzelne Dokument eine solche Datenbanklassenhierarchie instantiiert wird. Aus diesem Grund ist es nicht sinnvoll Operationen wie Volltextsuchen über die Datenbank durchzuführen, obwohl dies generell möglich wäre. Die Leistungsgrenzen der Datenbank wären schnell erreicht und eine Suche würde immense Ressourcen beanspruchen.
Die Idee für das hier entwickelte Datenmodell ist an das Projekt VODAK angelehnt. Das SGML-Datenbanksystem VODAK, das unter Kapitel 2.2.2 bereits beschrieben wurde, instantiiert für jedes SGML-Dokument eine Objekthierarchie, die der Struktur des Dokuments entspricht. Das vorgestellte Datenmodell des Speichers speichert ebenfalls die Objekthierarchie, jedoch wird die Hierarchie durch einfaches Verknüpfen (fortlaufende Nummer, Bruder, Sohn) und nicht durch Vererbung und Aggregation von Objekten realisiert.
VODAK bietet eine wesentlich mächtigere und komfortablere Verarbeitung von SGML-Dokumenten. Aufgrund der proprietären Schnittstellen und der Komplexität des VODAK-Systems, konnte das System jedoch keine Verwendung finden.
Die Eigenschaften des in diesem Abschnitt entwickelten Datenmodells im Überblick:
Dokumente sollten prinzipiell einmal strukturiert in der Datenbank und einmal unstrukturiert als Bitstrom (Datei) im Speicher abgelegt werden. So können effiziente Volltextsuchen durch Einsatz entsprechender Indizierer und strukturierte Suchen unter Verwendung der Datenbank durchgeführt werden. Allgemein können durch diese Vorgehensweise alle sequentiell auf den Dokumenten auszuführenden Operationen effizienter auf den als Bitstrom gespeicherten Informationen durchgeführt werden. Alle Operationen, die gezielt auf bestimmte Teile oder der gesamten Struktur des Dokuments aufsetzen, können effizienter auf den in der Datenbank gespeicherten Daten ausgeführt werden.
Diese Effizienz und Flexibilität bzgl. des Zugriffs auf die SGML-Dokumente kostet jedoch den doppelten Speicherplatz für jedes Dokument, auf den zur Ablage bestimmten Massenspeichern.